2022. 9. 19. 01:12ㆍ개발 관련 책 읽기/리눅스 커널 내부구조
스케줄링에 대해서 알아보도록 하자
스케줄링은 여러 개의 태스크들 중에서 다음번 수행시킬 태스크를 선택하여 CPU라는 자원을 할당하는 과정을 말한다.
리눅스의 태스크는 실시간 태스크와 일반 태스크로 나뉘며 각각을 위한 별도의 스케줄링 알고리즘이 구현되어 있다. 실시간 태스크는 항상 일반 태스크 보다 우선하여 실행됨을 알아야 한다.
일반적으로 OS는 스케줄링 작업 수행을 위해, 수행 가능한 상태의 태스크를 자료구조를 통해 관리한다
리눅스에서 이 자료구조를 런 큐 라고 한다. 런큐는 한 개 혹은 여러 개 존재할 수 있으며, 자료구조의 모양이나 괸리 방법 역시 달라진다.
태스크가 처음 생성되면 init_task를 헤드로 하는 이중 연결 리스트에 삽입된다.
리눅스 시스템에 존재하는 모든 태스크들은 int_task에 연결되어 있다.
밑의 그림을 보면 구조를 알수 있을것이다.
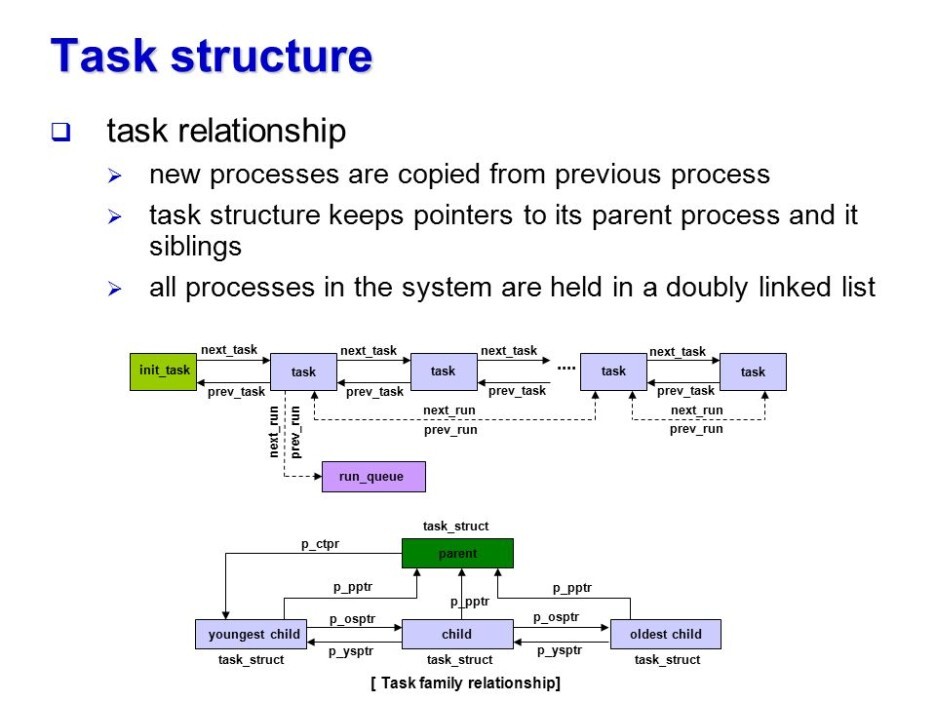
멀티 CPU환경에서 런 큐가 여러 개라면 새롭게 생성된 태스크는 어느 런 큐에 삽입될까??
부모 태스크가 존재하던 런 큐로 삽입되는 것이 효율적일것이다.
그 이유는 자식 태스크가 부모 태스크와 같은 CPU에서 수행될 때 더 높은 캐시 친화력(cache affinity)를 얻을 수 있기 때문이다.
리눅스 에서는 task_struct의 cpus_allowed 필드에 태스크가 수행될 수 잇는 CPU의 번호가 들어있고,
이를 이용해 삽입될 런 큐를 결정하게 된다. 새로 생성된 태스크의 cpus_allowed 필드는 wake_up_new_task()가 수행될 때 부하 균등을 고려하여 수정된다.
스케줄러가 수행되면 해당CPU의 런 큐에서 다음번 수행시킬 태스크를 골라낸다.
이때 두 가지 고려사항이 있다.
1.어떤 태스크를 선택할 것인가
->리눅스에서 일반 태스크를 위해 CFS(Completely Fair Scheduler)를 사용하며 실시간 태스크를 위해서는 FIFO,RR,DEADLINE 정책을 제공한다.
2.런 큐간에 부하가 균등한지 에 대한 문제
->부하가 균등하지 않을 시 해결 방법에 대한 문제이다. 이를 위해서 리눅스는 부하 균등 기법을 제공하며,load_balance()함수가 이를 담당하고 있다. 이 함수는 특정 CPU가 많은 작업을 수행하고 있느라 매우 바쁘고 다른 CPU는 한가하다면 다른 CPU로 태스크를 이주 시켜서 시스템의 전반적인 성능 향상을 야기해준다.
CPU의 스케줄리은 공정해야 하며,효율적이어야 가장 높은 처리율(throughput)을 낼 수 있을 것이다.
또한 가장 급한 태스크를 한가한 태스크 보다 먼저 수행될 수 있도록 해준다면 보다 높은 반응성을 보일것이다.
그러면 어떤 기준에 근거하여 태스크를 선택하는 것일까??
이를 위해 task_struct 구조체는 policy,prio,rt_priority 등의 필드가 존재한다.
policy필드는 이 태스크가 어떤 스케줄링 정책을 사용하는지 나타낸다
리눅스는 실시간 태스크를 위해 3개 일반 태스크를 위해 3개 ,총 6개의 스케줄링 정책이 존재한다
(FIFO,RR,DEADLINE) (NORMAL,IDLE,BATCH)
리눅스의 실시간 태스크란 SCHED_FIFO,SCHED_RR,SCHED_DEADLINE 정책을 사용하는 태스크를 의미한다. 즉 , 실시간 태스크를 생성하는 별도의 함수가 존재하는 것이 아니라 sched_setscheduler()등의 함수를 통해 태스크의 스케줄링 정책을 위 3개중 하나로 바꾸게 되면 실시간 태스크가 되는것이다.
실시간 태스크는 우선순위 설정을 위해 rt_priority 필드를 사용한다. rt_priority는 0~99까지의 우선순의를 가지며, 태스크가 수행을 종료하거나, 스스로 중지,자신의 time slice를 다 쓸 때까지(SCHED_RR 정책에만 해당) CPU를 사용한다 .
RR 인 경우 동일 우선순위를 가지는 태스크가 복수개의 경우 time slice 기반으로 스케줄링 된다. 만약 동일 우선순위를 가지는 RR 태스크가 없는 경우 FIFO와 동일하게 동작한다. 또한 실시간 정책을 사용하는 태스크는 고정 우선순위를 가지게 되며 우선순위가 높은 태스크가 낮은 태스크보다 먼주 수행됨을 보장한다.
우선순위가 가장 높은 태스크를 어떻게 찾는 것이 효율적일까??
init_task에 연결되어 잇는 모든 태스크에서 가장 높은 우선순위를 갖는 태스크를 찾으면 된다
하지만 태스크의 개수가 늘어날수록 탐색 시간도 선형적으로 증가하게 되므로 O(n) 비효율적이다.
이러한 단점을 해결하는 방법은 FIFO 혹은 RR 정책을 사용하는 실시간 태스크들이 가질 수 있는 모든
우선순이 레벨(0~99)을 표현할 수 있는 비트맵을 준비한다.
태스크가 생성되면 비트맵에서 그 태스크의 우선순위에 해당하는 비트를 1로 set한 뒤,태스크의 우선순위에 해당하는 큐에 삽입된다.스케줄링 하는 시점이 되면 커널은 비트맵에서 가장 처음 set되어 있는(존재하는 태스크들 중에서 가장 우선순위가 높은)비트를 찾아 낸 뒤,그 우선순위 큐에 있는 태스크를 선택하게 된다.
시간복잡도는 고정된 크기의 비트맵에서 수행되므로 상수시간에 가능하므로 스케줄링 작업은 고정시간 내에 완료가 된다.
DEADLINE 정책은 가장 급한 태스크를 스케줄링 대상으로 선정한다.
수행중이던 A라는 태스크에 할당되어 있던 time slicer가 모두 소진되거나,I/O 작업을 위해서 대기되는 상태가 되면 커널은 새로운 태스크 B를 선택하여 CPU를 할당해준다.
이렇게 수행중이던 태스크의 동작을 멈추고 다른 태스크로 전환하는 과정을 문맥 교환이라 부른다
커널은 태스크가 문맥교환 되는 시점에 어디까지 수행했는지,현재 CPU 레지스터 값은 얼마인지 저장해둔다. 이를 문맥 저장이라고 한다.
즉, 스케줄링이 일어나면 문맥 교환이 발생하고, 문맥 교환 시엔 현재 수행 중이던 태스크의 문맥을 저장해 두어야 한다. 이때 문맥은 CPU 레지스터 즉, H/W context를 뜻한다
task_struct 에 H/W context를 저장하기 위한 필드를 만들어 두었다. task_struct의 thread 필드이며 이 필드는 thread_struct를 형태로 정의된다 아래 그림을 보고 확인하자
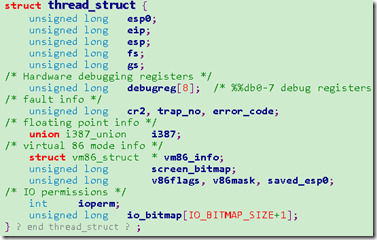
thread_struct 구조체는 태스크가 실행하다가 중단되어야 할 때 태스크가 현재 어디까지 샐행했는지 기억하는 공간이다.
그렇다면 어떤 정보를 유지 해야 할까?
CPU의 PC,SP,범용레지스터 값들 CPU상태를 나타내는 eflags,세그먼트 관리하는 cs,ds등의 레지스터 내용도 기억해야한다.
결국 thread_struct가 이러한 정보를 기록할 수 있는 필드들로 구성되어 있는 것이다
예를들어 A태스크가 수행 중 B 태스크로 문맥교환이 일어난다면 몇번의 CPU 저장/복원 과정이 필요할지 알아보자.
- A태스크가 커널 레벨로 상태 변화를 해야한다(스케줄링 & 문맥 교환 코드가 모두 커널에 있으므로) ->태스크에 A를 위해 할당되어 있떤 커널 스택에 CPU 레지스터가 정보가 저장된다 (Save #1)
- 커널이 스케줄링 코드를 수행하고 다음번 수행 대상으로 TASK B를 선정하여 문맥 교환을 하게 되면 TASK A의 CPU 레지스터 정보를 task_struct.thread(thread_struct)구조에 저장한다( Save #2)
- Task B 역시 이러한 과정을 거쳐 문맥을 저장했으므로 Task B의 task_struct.thread 구조를 이용하여 CPU 레지스터 정보를 복원한다(Restore #1)
- 그런뒤 커널 수준 작업이 끝났다면 다시 유저 레벨로 돌아오게 되고 TASK B의 커널 스택에서 CPU 정보를 복원시킴으로써 다시 수행하게 된다.(Restore #2)
두 태스크 간의 문맥 교환은 총 4번의 CPU 레지스터 저장/복원이 발생하게 된다 (저장 2 복원 2)
시그널에 대하여 알아보자.
시그널은 태스크에 비동기적인 사건의 발생을 알리는 메커니즘이다.
태스크가 시그널을 원활히 처리하려면 3가지 기능을 지원해야한다
1.다른 태스크에게 시그널을 보낼 수 있어야 한다 -> 리눅스에서 sus_kill() 시스템 콜을 제공한다
2.자신에게 시그널이 오면 수신할 수 있어야 한다 -> task_struct에 signal,pending이라는 변수가 존재
3.자신에게 시그널이 오면 처리할수 잇는 함수를 지정할수 있어야 한다.
->sys_signal() 시스템 콜 제공,task_struct 내에 sighand라는 변수가 존재한다.
리눅스는 64개의 시그널을 지원한다.
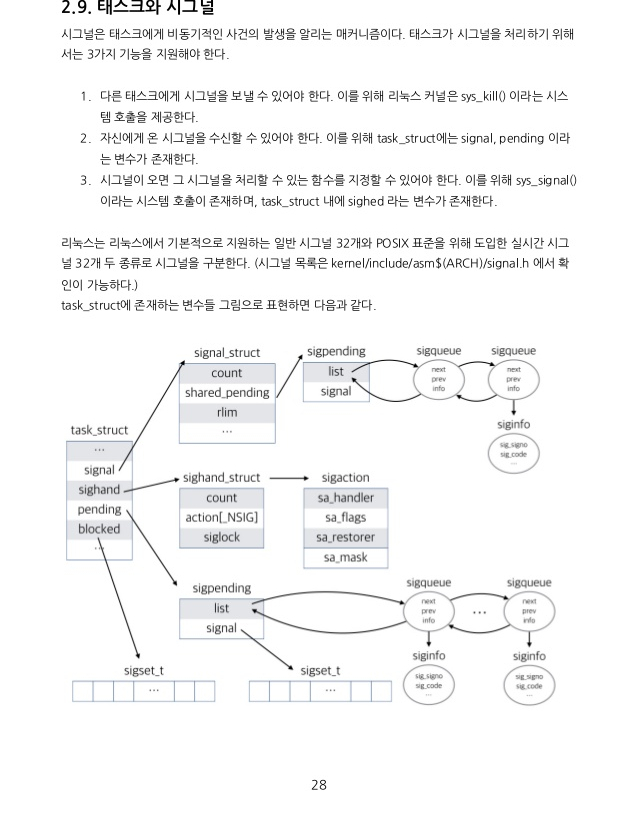
사용자가 쉘 프롬프트에서 $ Kill PID 와 같은 명령어를 사용하여 특정 PID를 가지고 있는 태스크를 종료시키려 한다고 가정해 보자. 이때 사용자는 PID를 공유하고 있는 쓰레드들(죽, 쓰레드 그룹)이 모두 종료될것이다. 리눅스에서 PID는 실제로는 tgid를 의미한다. 띠라서 PID가 같은 태스크들은 의미상 같은 쓰래드 그룹임을 의미한다. 그러므로 PID를 공유하고 있는 모든 쓰레드(쓰레드 그룹)간에 시그널을 공유하는 메커니즘이 필요하다.이렇게 여러 태스크들 간에 공유해야 하는 시그널이 도착하게 되면 이를 task_struct 구조체의 signal 필드에 저장해 둔다. 이러한 시그널을 보내는 작업은 sys_kill()과 같은 시스템 호출을 통해서 이뤄진다.
반대로 특정 태스크에만 시그널을 보내야하는 경우라면 어떨까?
이런 경우를 위해 공유하지 않는 시그널은 task_struct 의 pending 필드에 저장해 둔다.
시그널을 signal 필드나 pending 필드에 저장할 때는 시그널 번호 등을 구조체로 정의하여 큐에 등록하는 구조를 택하고 있으며,이를 위해 sys_tkill()과 같은 시스템 콜을 도입하였다.
한편 각 태스크는 특정 시그널이 발생했을 때 수행될 함수 즉, 시그널 핸들러를 지정할 수 있다.
이때 설정 함수는 sys_signal()이다. 태스크가 지정한 시그널 핸들러는 task_struct의 sighand 필드에 저장된다. 또한 blocked 필드를 통해 특정 시그널을 받지 않도록 설정도 가능하다.
인터럽트와 트랩 시그널 간의 차이점은 무엇일까?
인터럽트와 트랩이 Event를 커널에게 알리는 방식이라면 시그널은 Event를 태스크에게 알리는 방식.
'개발 관련 책 읽기 > 리눅스 커널 내부구조' 카테고리의 다른 글
| Chapter 4 - 메모리 관리 (2) (0) | 2022.09.19 |
|---|---|
| Chapter 4 - 메모리 관리(1) (0) | 2022.09.19 |
| Chapter 3 - 태스크 관리(3) (0) | 2022.09.19 |
| Chapter 3 - 태스크 관리(2) (0) | 2022.09.19 |
| Chapter 3 - 태스크 관리(1) (0) | 2022.09.19 |