2022. 5. 13. 17:29ㆍ개발 관련 책 읽기/친절한 SQL 튜닝
이 시리즈는 친절한 SQL 튜닝 (https://book.naver.com/bookdb/book_detail.nhn?bid=13650217) 책을 읽고 정리하여 공유하고자 합니다. 좀 더 자세히 알고 싶으신 분들은 책을 통해 확인부탁드립니다. 😊😊
자 시작해볼까요!
SQL 튜닝의 핵심은 랜덤 I/O와의 전쟁이다.
SQL 튜닝에서 랜덤 I/O가 그만큼 중요하다.
먼저, 인덱스를 이용한 테이블을 액세스 하는 실행계획을 보자.
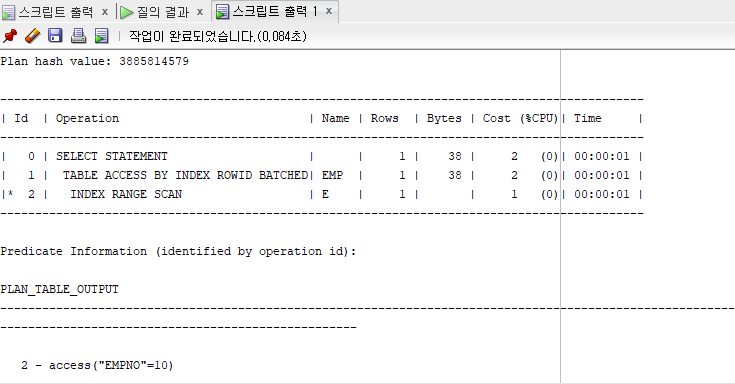
위의 그림 1을 보면 인덱스(E)를 통한 Index Range Scan을 하는 과정을 볼 수 있다.
*EMP 테이블에 E라는 인덱스 생성하였음(create index E on EMP(EMPNO);)
위의 'Table Access BY INDEX ROWID'라고 표시된 부분이 ROWID를 통해 테이블 접근한다는 것을 볼 수 있다.
그러면 ROWID 어떤 식으로 구성돼있길래 테이블에 접근할 수 있을까라는 의문이 생기게 된다. (나만 그런가? ^^;;)
ROWID 구조가 궁금하지 않은가? 아래 그림 2를 같이 보자~
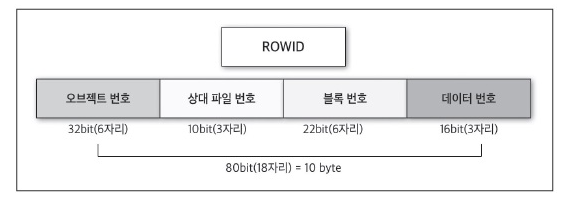
그림 2의 ROWID 구조를 보면 OBJECT 번호 + 데이터 파일 번호 + 블록 번호+ 데이터 번호(로우 번호)로 총 10 Byte로 구성되어 있다.
각각 번호에 대해서 알아보자. (아래표 참고)
|
구분
|
설명
|
|
오브젝트 번호
|
32bit(6자리)로 구성된 번호로 해당 데이터가 속하는 오브젝트 번호다. 오브젝트 별로 유일한 값(Unique)을 가진다
|
|
상대 파일 번호
|
10bit로(3자리)로 구성된 디스크 상의 물리적인 파일 번호(데이터 파일 번호)
|
|
블록 번호
|
22bit(6자리)로 구성된 익스텐드 내의 블록 번호
|
|
데이터 번호
|
16bit(3자리)로 구성된 블록 안에 있는 로우의 순차적인 번호
|
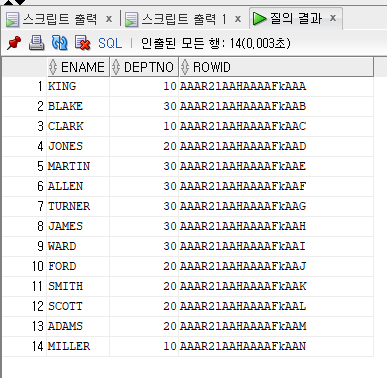
위의 그림 3을 보면 emp 테이블을 조회하고 조회 칼럼에 rowid를 추가하셔 조회하였다.
첫 번째 행의 rowid를 보면 'AAAR2lAAHAAAAFkAAA'로 구성되어 있는데 분석해 보면
1) object 번호(6자리)
->AAAR2lAAHAAAAFkAAA
: 오브젝트 별로 유일한 값이다. EMP 테이블의 모든 데이터의 ROWID는 'AAAR2l'로 시작한다.
2) 상대 파일 번호(3자리)
->AAAR2lAAHAAAAFkAAA
:EMP 테이블이 저장돼 있는 테이블 스페이스 상대 파일 번호다. EMP 테이블의 데이터일지라도 테이블의 익스텐트(EXTENT)가 다른 데이터 파일에 할당될 수 있다. 이 경우 해당 값은 서로 다르게 할당된다.
3) 블록 번호(6자리)
->AAAR2lAAHAAAAFkAAA
:데이터가 저장되어 있는 블록 번호를 가리킨다.
4)로 우 번호(3자리)
->AAAR2lAAHAAAAFkAAA
:블록 내의 로우 번호를 가리킨다.
정리하자면, RowID 구조를 통한 파일 번호, 블록 번호, 로우 번호를 접근하여 데이터 접근이 가능하게 되는 것이다.
Data Blcok Address(DBA=데이터 파일 번호+블록 번호)를 통해 디스크 상에서 블록을 찾는데 디스크 I/O 자체가 메모리 접근 보다 굉장히 느린 비효율적인 I/O를 하므로 DB 버퍼 캐시를 활용하여 I/O 성능을 높여야 한다. 그래서 블록을 읽을 때의 순서는
1. 버퍼 캐시에 해당 블록이 있는지 확인한다.
2. 읽고자 하는 DBA를 해시 함수에 입력해서 해시 체인을 찾고 거기서 버퍼 헤더를 찾는다.
3. 버퍼 헤드를 통해 실제 데이터가 담긴 버퍼 블록을 찾는다.(포인터)
4. 버퍼캐시에 해당 블록이 없을 경우 디스크 I/O를 통해 버퍼 캐시로 적재한다.
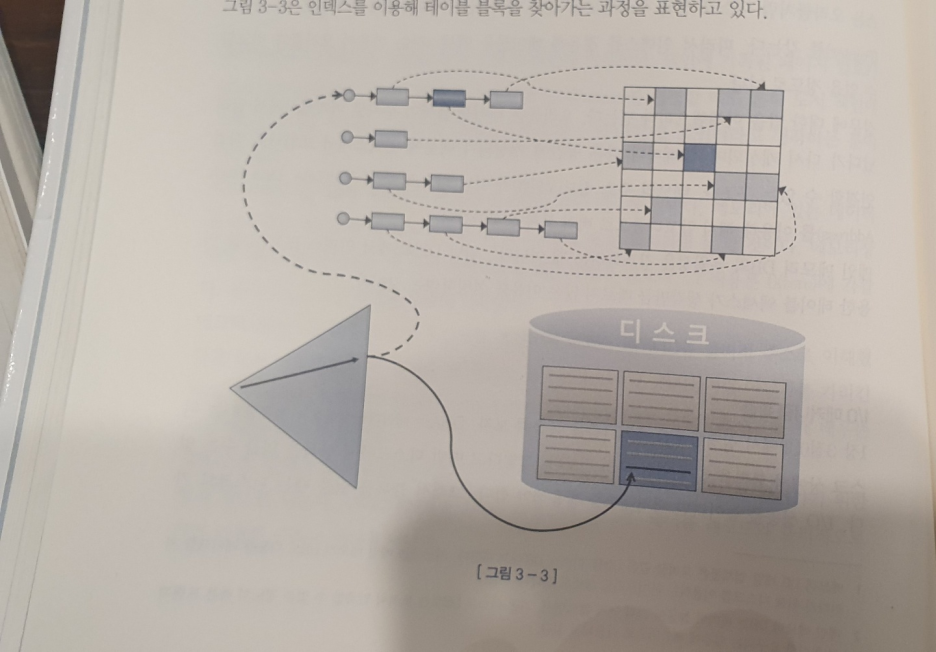
위의 그림 4는 인덱스를 이용한 테이블 블록 찾는 과정을 도식화한 것인데 핵심은 인덱스로 테이블 블록을 액세스 할 때는 인덱스 수직적 탐색 + 수평적 탐색으로 인해 접근한 Leaf 블록에서 얻은 RowID를 분해해서 DBA 정보(데이터 파일 번호+블록 번호)를 얻고 접근하는 것이고
테이블을 Full Scan 할 때는 익스텐드 맵을 통해 읽을 블록들의 DBA 정보를 얻는 것이다.
*테이블 레코드를 찾기 위해 매번 DBA 해싱과 래치 획득 과정을 반복을 통해 레코드를 접근해야 한다.
그리고 동시 액세스가 심할 때는 캐시버퍼 체인 래치와 버퍼 Lock에 대한 경합까지 발생한다.
이처럼 인덱스 ROWID를 이용한 테이블 액세스는 고비용 구조이다.
'개발 관련 책 읽기 > 친절한 SQL 튜닝' 카테고리의 다른 글
| 4. NL 조인[조인 튜닝] (0) | 2022.09.19 |
|---|---|
| 3. 부분 범위 처리[인덱스 튜닝] (0) | 2022.09.19 |
| 2. 인덱스 클러스터링 팩터[인덱스 튜닝] (0) | 2022.09.19 |